
Small Business Banking Data for Explainable Credit Risk Scoring
Published:
Executive Summary
XGBoost with monotonic constraints gives 7% higher KS compared to traditional score-card model and explainability problem is being solved using SHAP explanations.
Introduction
The complex machine learning models provide higher predictive power but it has less explainability power compared to traditional scorecards. Traditional scorecards are good at explaining the scores and attributing the variables to the score. Machine Learning Models generally have higher predictive power than traditional scorecards but lack explaining parts as it uses tree based structure to create the cuts.
Methodology and Results
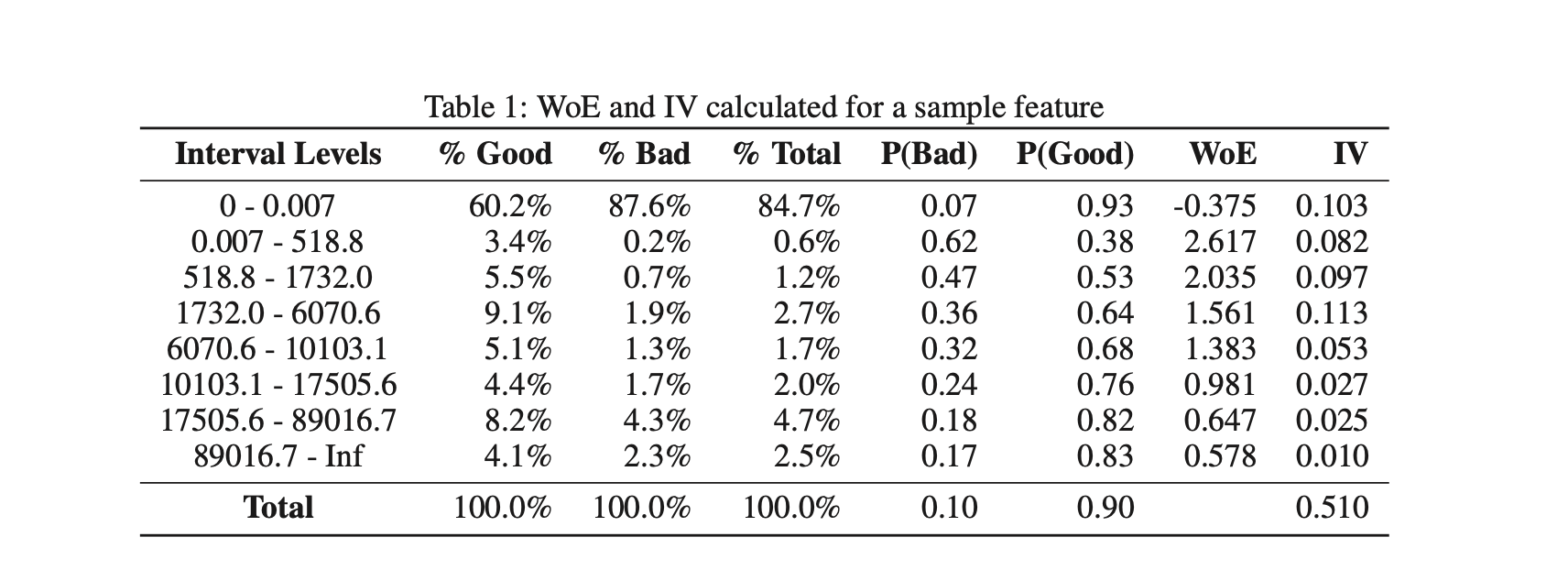
Traditional scorecards use WOE and Information on the features as independent features. Generally, cuts are used to increase IV. Manual adjustment of bins is then applied to satisfy the monotonic relationship requirement. Missing and extreme feature values can be binned separately and both categorical and continuous variables can be with optimal binning.
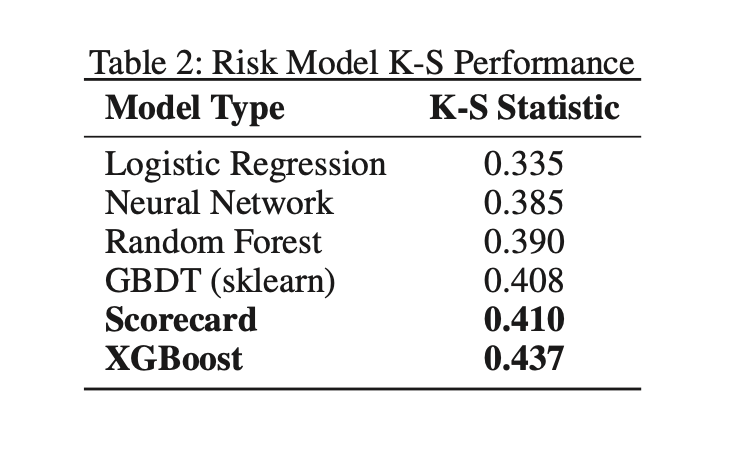
Non-Linear Risk Models(such as XGBoost, Catboost, and LighGBM) may perform better than score-card models when feature interactions are complex. XGBoost has produced higher KS by 7%. Neural Networks performed not so well compared to tree-based models given the number of data points was lower compared to features.
Adverse Action Codes are assigned based on the higher value of the features that increase the risk or lower the risk. Construction of score-card having property of the monotonic relationship between features and scores.
Explaining the XGBoost model can be done using two techniques:-
- LIME generates random neighbor samples to weigh features according to distance from the record in question.
- SHAP calculates the feature attribution using Shapley Values. Features with the highest Shapley Values are then mapped to the AA reason code.
The monotonicity requirements that ensure credit decisions have acceptable explanations were satisfied using features in XGBoost that force predictions to monotonically increase or decrease with respect to each feature when other features are constant. For a tree-based model, the right child’s value is constrained to be higher than the left child’s value for each split of a particular feature. Model monotonicity constraints give a higher KS by 8%.
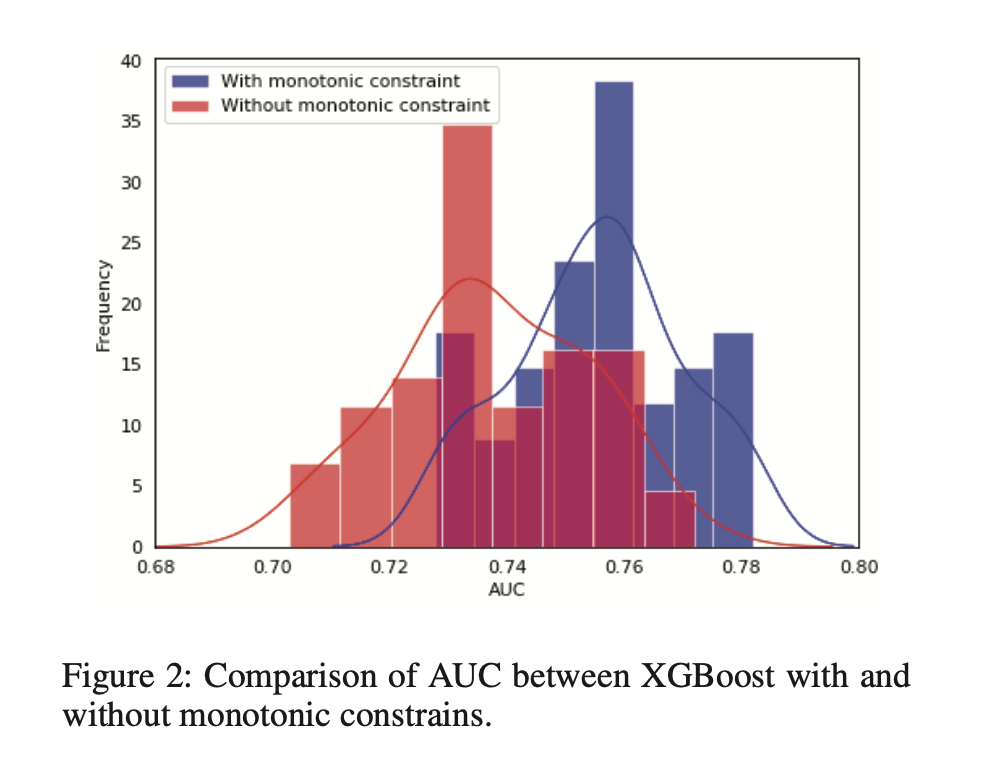
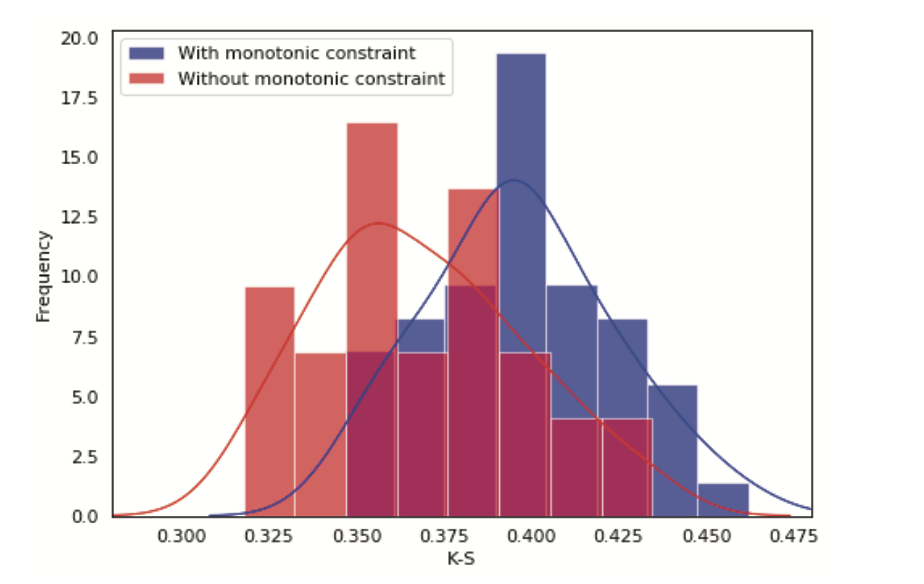
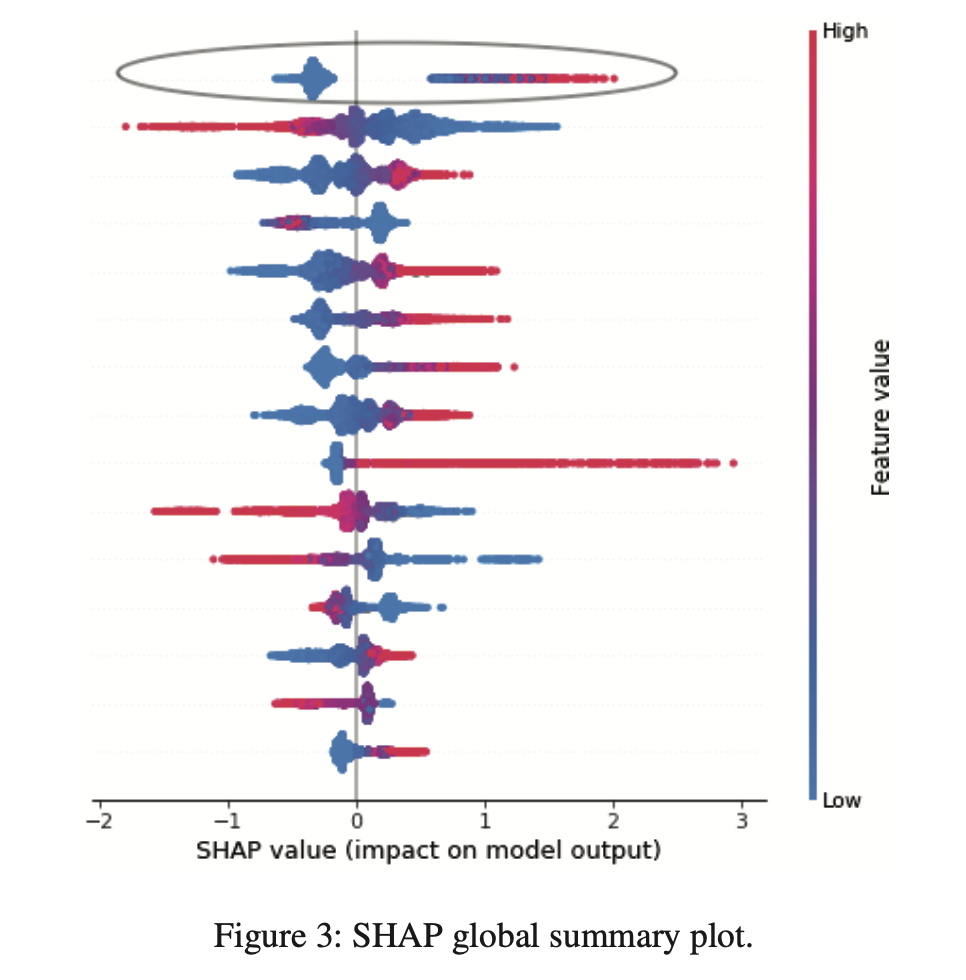
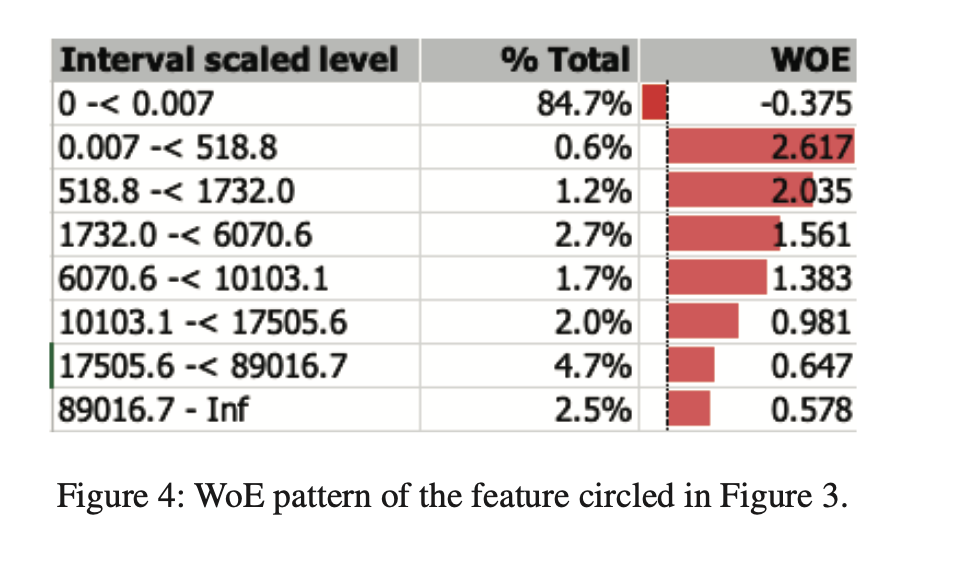
It is also important to understand the direction of impact with highly imbalanced distribution such as the high contribution of missing values. It is possible that high contribution might be from missing values that have negative WOE but larger values of the variable lead to lower risks. We can handle this by creating a separate dummy feature.
Scorecard vs XGBoost Explanations
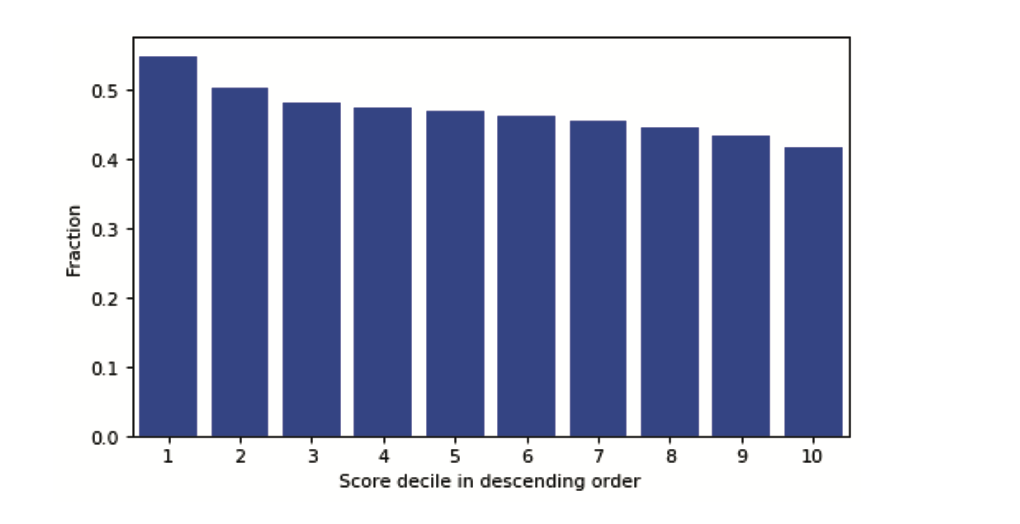
Binning the population based on the scores and comparing the agreement on the features provide a clear idea of the efficacy of the model. For risky deciles, it has more agreement vs less risky declines. Finding more risky customers is easy very less risky customers, therefore, we see more agreement in the risky deciles.
References
- https://ojs.aaai.org/index.php/AAAI/article/view/7055